Histórico da Página
Índice:
| Índice | ||
|---|---|---|
|
Objetivo:
O objetivo deste documento é trazer uma visão do que é e como funciona a Arquitetura N Camadas. De como configurar o ambiente em suas estações para correto funcionamento das aplicações neste cenário.
Introdução:
O que é a Arquitetura N Camadas:
Anteriormente, na Arquitetura Cliente‐Servidor, a camada cliente acessava diretamente a camada de Banco de Dados, além de todos os processos como: abertura de formulários, acesso a dados, regras de validação, cálculos e relatórios entre outros.
Na Arquitetura N camadas, apesar da complexidade do ambiente, a divisão das tarefas possibilita maior distribuição de processamento do sistema.
Cliente - Na camada cliente, temos apenas os formulários que serão abertos na execução do programa.
APP - Na camada aplicação, a execução da Regra de Negócio e Cálculos além de fazer a comunicação com a Camada de Banco de Dados.
JOB - Na camada Jobs, a execução dos processos e a comunicação com a Camada de Banco de Dados.
Abaixo exemplo da arquitetura em N camadas:

Servidor de Jobs:
O que é:
É um dos serviços executados pelo Host em background, na arquitetura N camadas, esse serviço é habilitado somente no servidor de Jobs. É responsável por executar os processos submetidos pelos aplicativos, que entram em uma fila de execução (GJOBXEXECUCAO).
Como Funciona:
- GJOBX – Tabela onde são registrados os processos.
- GJOBXEXECUCAO – Tabela que controla a fila dos processos.
Separação entre JobServer e AppServer:
Como é Definido:
- JobServer3Camadas habilitado em todos os configs;
- A execução de Jobs tem de estar desabilitada no AppServer;
- A execução de Jobs deve estar habilitada no JobServer;
- Todos os clientes apontados para o AppServer;
Vantagens:
- Aproveitamento de hardware.
- Isolamento para identificar problemas.
Veja mais sobre: Configuração do Jobserver na Linha RM e Gerenciamento de Alias
Instalação em N camadas:
Servidor de Aplicação:
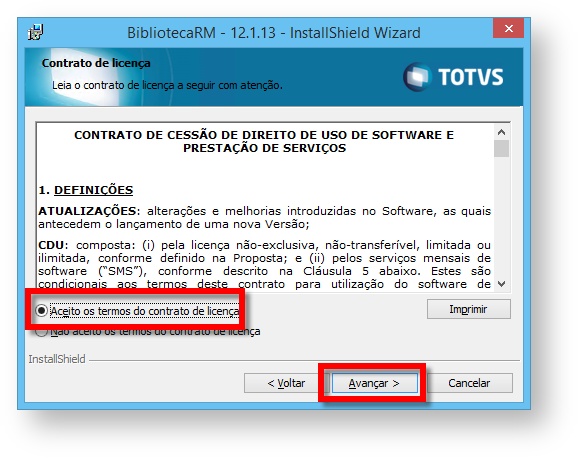
Instale a Biblioteca RM no Servidor de Aplicação (no momento de instalação, selecione "Ambiente N camadas | Servidor de Aplicação (App Server)"). Ao selecionar Modo Servidor de Aplicação, somente os arquivos necessários serão copiados nesta instalação , ou seja, arquivos necessários para a execução do Host.
Passo a Passo para instalação do RM em N camadas Servidor de Aplicação:
| Informações | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|















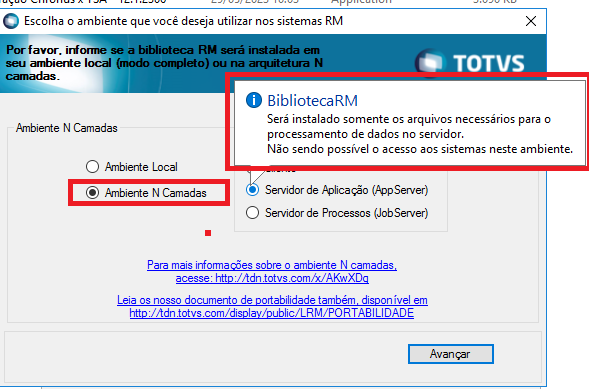
Servidor de Jobserver:
É responsável pela execução dos Jobs/Processos, e comunicação direta com o banco de dados.
Abaixo as configurações que diferenciam o Jobserver do AppServer:

Instalação Jobserver:
|

Servidor de Jobserver:
É responsável pela execução dos Jobs/Processos, e comunicação direta com o banco de dados.
Abaixo as configurações que diferenciam o Jobserver do AppServer:
Instalação Jobserver:
Passo a Passo para instalação do RM em N camadas Servidor JobServer::
| Informações | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|

Passo a Passo para instalação do RM em N camadas Servidor JobServer::
| Informações | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Existem duas formas de verificarmos se o processamento de Jobs está ativo:
- Gerenciamento de Alias:
Para que o processo seja iniciado juntamente com o host, é necessário acessar o gerenciamento de Alias e verificar que a flag "Habilitar Processamento de Jobs" estará marcada.
| Aviso | ||
|---|---|---|
| ||
Quando a configuração for feita pelo alias, o Host processará somente o Job da base onde a flag estiver marcada. |
Configurações do alias abaixo:


- Cockpit:
Podemos utilizar o Cockpit para iniciar o processamento de Jobs de forma manual.
Exemplo abaixo:

| Aviso | ||
|---|---|---|
| ||
Todas as máquinas que estiverem executando um Host serão adicionadas ao Cockpit, nele é possível identificar se as máquinas estão ou não executando processos e se estão processando Jobs locais ou não. |
Servidor Client:
Na camada cliente temos apenas os formulários que serão abertos na execução do programa. Ao instalar a Biblioteca RM em cada Cliente (no momento de instalação, selecionar "Ambiente N Camadas | Client") será necessário informar o servidor de aplicação e porta de comunicação (Padrão 8050).
Ao selecionar o modo Client serão copiados para a pasta de instalação somente os arquivos necessários para execução dos sistemas. O sistema será configurado para direcionar todo o processamento de dados para o servidor de aplicação, ou seja, o processamento de dados será realizado na máquina em que a Biblioteca for instalada na opção App Server.
Passo a Passo para instalação do RM em N camadas Servidor Client:
| Informações | ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||
|


Alias.dat:
As configurações do RM.AliasManager.exe, são armazenadas no arquivo Alias.dat.

| Aviso | ||
|---|---|---|
| ||
Caso não exista o arquivo “Alias.dat”, ou um alias para o banco de dados em questão, essa configuração será criada automaticamente assim que qualquer tela de processos for aberta, tornando esse processos transparente para o usuário. |
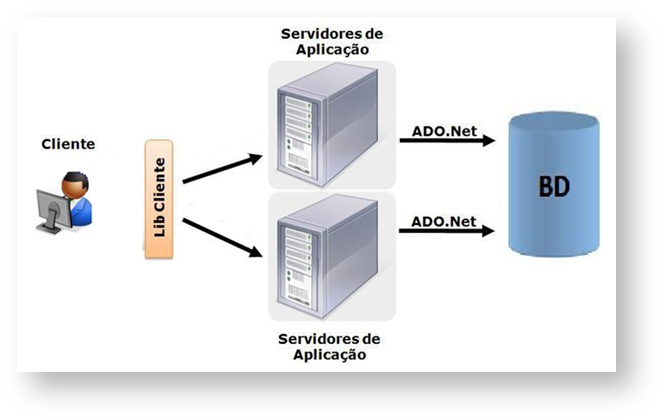
Balanceamento Nativo:
- Balanceamento Nativo:
Configuração para um cliente utilizar dois servidores de APP, fazendo com que seja distribuindo a carga entre eles. Melhorando a performance do sistema.
Exemplo abaixo de como será o funcionamento do sistema:
| Aviso | ||
|---|---|---|
| ||
Nesse cenário o sistema fará o balanceamento por requisição, alternando as requisições entre os servidores. |
- Como Configurar:
A máquina cliente será apontada para dois ou mais servidores de aplicação. essa configuração pode ser realizada durante a instalação da Biblioteca RM em modo client ou através do arquivo ".config" do aplicativo (exemplo: C:\totvs\CorporeRM\RM.Net.exe.config), inserindo as tags "PORT" e "HOST" apontando para o outro servidor.
Exemplo abaixo:

| Aviso | ||
|---|---|---|
| ||
Lembrando que poderá haver mais de dois servidores de aplicação. Neste caso, é necessário continuar identificando as tags. Exemplos: Host2, Host3, Port2 e Port3. |
Isolamento de Processo:
- JobRunner:
O isolamento de processo consiste em habilitar o RM.Host.JobRunner para execução das threads/processos realizados pelos usuários. Dessa forma garantimos que o serviço do Host mantenha-se estável e dedicado somente à abertura de telas e realizações de alguns cálculos de regras de negócio dos aplicativos.
- Habilitação do Isolamento de Processo:
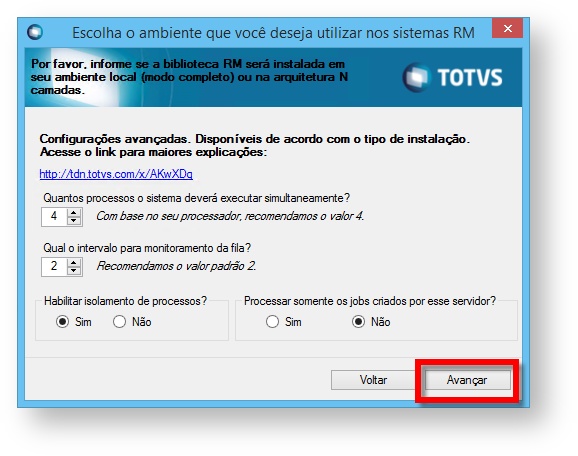
O isolamento de processo pode ser habilitado durante a instalação da Biblioteca Rm em modo "JobServer" ao marcar a opção "Habilitar Isolamento de Processo" (5º passo da instalação como JobServer) ou incluindo as seguintes tags nos arquivos de configuração do Host (RM.Host.Service.exe.config ou RM.Host.exe.config) são eles:
- ENABLEPROCESSISOLATION
- ISOLATEPROCESS
Exemplo abaixo de um arquivo de configuração do host com o isolamento de processo habilitado:

Afinidade de Processo:
É possível através do Cockpit, definir que um servidor de Job terá uma afinidade de processo, ou seja, ele será responsável pela execução de determinados processos de forma exclusiva, além dos demais processos. . Se configurada a afinidade, o job server só executará Jobs que respeitam essa afinidade.
Exemplo:
- Definir que o servidor 1 de Job será responsável pela execução do processo de "Executar Relatório", além dos demais processos.
- Dessa forma, o servidor 2 de Job executará todos os processos exceto o de "Executar Relatório".
Exemplo desta configuração na imagem abaixo:

Configurações:
Configurações Gerais:
Para garantir o correto funcionamento do sistema em ambiente N camadas, os arquivos de configurações devem ser configurados respeitando as orientações a seguir.
Aliaspath:
Define um único alias.dat para ser utilizado por todos os Servidores de aplicação do ambiente. Para uso, deve-se adicionar a Tag "Aliaspath" nos arquivos "RM.AliasManager.exe.config", "RM.Host.exe.config" e "RM.Host.Service.exe.config".
Exemplo: <add key=“Aliaspath” value=“\\Servidor\Pasta” />
| Aviso | ||
|---|---|---|
| ||
Como a configuração dos Alias no Servidor de APP é diferente do Servidor de Jobs, deve-se utilizar um Alias para o(s) servidor(es) de Jobs e outro para os servidores de APP. |
FileServerPath:
Define Como anteriormente explicado durante os passos da instalação em modo Server (Job e APP) está tag define um único diretório para geração e leitura de arquivos temporários, assim todos os Hosts do ambiente irão gerar os arquivos somente neste diretório. Em ambientes N camadas, de-se adicionar a Tag "FileServerPath" " deve estar presente nos arquivos ( RM.Host.exe.config ou RM.host.Service.exe.config ) de todos os servidores de APP e Job.
Exemplo: <add key=“FileServerPath” value=“\\Servidor\Pasta” />
LogPath:
Define o caminho onde serão gerados os log's do sistema.
Exemplo: <add key=“LogPath” value=“\\Servidor\Pasta” />
- LOCALIZATIONLANGUAGE:
Determina qual linguagem o sistema irá funcionar independente da linguagem em que sistema operacional esta configurado.
Exemplo: <add key=“LOCALIZATIONLANGUAGE” value “pt-BR” />
- ENABLECOMPRESSION:
Habilita compressão de dados para melhorar desempenho de rede, contudo o custo para compactação e descompactação dos dados em redes Gigabits, pode ser superior a transferências sem a compactação.
Exemplo: <add key=“ENABLECOMPRESSION” value “true” />
| title | Observação: |
|---|
Para redes de alta performance. Recomendamos o uso do EnableCompression como "False", onde os dados não necessitam ser comprimidos para serem trafegados.
Em rede restritas, deve-se alterar a tag para "True" visto que os dados serão comprimidos para serem trafegados, ajudando assim na performance., contudo o custo para compactação e descompactação dos dados em redes Gigabits, pode ser superior a transferências sem a compactação.
Veja mais sobre a compressão de dados em: Configurando a compressão de dados
Configurações Bases Oracle:
Visando melhorar a performance de acesso em bancos Oracle, existe um cache para armazenar dados do schema da base de dados. Este cache é necessário pois o "GetSchema" no Oracle tem um alto custo. Para correta utilização, deve-se parametrizar o Config do Host da seguinte forma:
UseDbSchemaCache:
Indica se o sistema guardará em cache os esquemas obtidos pelas consultas.
Exemplo: <add key="UseDbSchemaCache" value="true" />
DbSchemaCacheMaxSize:
Define a quantidade de schemas que serão guardados em cache.
<add key="DBSchemaCacheMaxSize" value=“5000"/>
| Aviso | ||
|---|---|---|
| ||
Apesar do valor default ser 100, o valor ideal de acordo com testes realizados é 4000. Este valor deve ser utilizado com bastante critério, se for muito grande, pode-se comprometer a performance do banco |
Principais Tabelas:
GJOBSERVER:
- Quantos Jobs estão sendo executados no momento.
- Quantos Jobs são executados simultaneamente pelo Host.
- Qual o intervalo de leitura da fila de processos.
- Qual é o servidor que distribui os processos.
GJOBX
- Nome do processo - Definido no Wizard.
- O processo é recorrente.
- Parâmetros do processo.
- Usuário que criou o Job.
GJOBXEXECUCAO
- Controla a fila
- Armazena o históricos de todos os processos.
Tabelas relacionadas a fila de processos
- GRELBATCH
- GJOBLOG
- GJOBXLOG
- GJOBXEXECUCAO
- GJOBXEXECUCAOHST (A partir da versão 12.1.31 - Veja em: Melhorias no funcionamento do Job)
- GJOBX
Tabela relacionada ao log de auditoria.
- ZLOG
Tabela relacionada ao Histórico de Cubo .Net.
- QCUBODATA
| Aviso | ||
|---|---|---|
| ||
Essas tabelas armazenam grande número de informações e por isso devemos executar o processo de manutenção. |
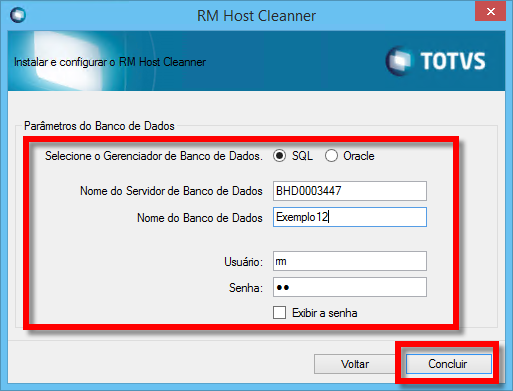
Veja também: RM.Host.Cleanner |
| Informações | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||
|
| Informações | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||
|
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas