Histórico da Página
| Informações | ||
|---|---|---|
| ||
Este recurso está disponível a partir da atualização 1.5.5 do TOTVS Fluig Plataforma. |
...
| Índice | ||||||
|---|---|---|---|---|---|---|
|
| Nota |
|---|
Este recurso está disponível a partir da Atualização 1.5.5 da plataforma fluig. |
Conceito
| ||
A partir das atualizações 1.6.5 Liquid, 1.7.0 Lake e 1.7.1 Crystal Lake, os select passados por constraint em dataset serão bloqueados pelo serviço. Orientamos a leitura da documentação Datasets acessando banco de dados externo que contém um exemplo da correta utilização do procedimento. |
Conceito
...
A sincronização de datasets tem como A sincronização de datasets tem como objetivo reduzir o número de acessos a serviços de dados fornecidos por produtos externos ao fluigà plataforma TOTVS Fluig. É uma prática comum trazer dados de sistemas externos para complementar informações do formulário de um processo ou realizar validações em eventos com base nas informações retornadas por este dataset.
Exemplificando
Em um exemplo mais específico, vamos supor que o usuário precisa informar no formulário de seu processo o centro de custo e que a lista dos centros de custo válidos está disponível em um sistema externo. Para que este usuário consiga informar um centro de custo válido ele deverá através de um formulário acessar um campo com pesquisas que por sua vez , será necessário:
- o usuário acessar o campo com pesquisas, através de um formulário;
- esse campo solicita informações para o dataset
...
- ;
- o dataset, quando executado através
...
- da plataforma, faz acesso ao serviço de dados do sistema externo.
Se este workflow possuir uma média de cinco mil abertura aberturas de processo por dia, teremos pelo menos cinco mil acessos a este sistema externo que, em muitos casos, acaba retornando sempre as mesmas informações ou tendo uma variação muito pequena de informações entre uma consulta e outra.
O desenho abaixo ilustra como funciona o ciclo de acesso do usuário a uma informação externa ao fluigà plataforma.

Figura 1 - Ciclo de acesso do usuário a uma informação externa à plataforma
Contudo, como tratam-se de sistemas externos não é possível para o fluig garantir tanto a performance quanto a disponibilidade desses serviços de dados. Eventuais problemas de performance ou disponibilidade impactarão o desempenho do fluig da plataforma TOTVS Fluig e podem até mesmo inviabilizar o uso de determinado processo workflow.
Sincronização de Datasets
...
No modelo de dados sincronizados, o fluig através por meio de uma tarefa agendada realiza é possível realizar a consulta do sistema externo e copia os dados retornados para uma tabela espelho criada dentro do banco de dados do fluigda plataforma.

Figura 2 - Tarefa agendada para consulta ao sistema externo
Uma vez que a primeira sincronização tenha sido concluída com sucesso, todas as consultas realizadas neste dataset não irão mais consultar o sistema externo, mas sim a tabela que foi espelhada pela tarefa agendada. Em nosso cenário hipotético caso o administrador do sistema opte por agendar a tarefa que atualiza a lista de centros de custo uma vez por dia. Após a sincronização a performance e a disponibilidade do sistema externo não afetarão mais a performance do fluig e da plataforma e dos sistemas workflow.
| Nota | ||
|---|---|---|
| ||
A Sincronização de datasets em tabelas do fluig só da plataforma não pode ser utilizada em datasets do tipo personalizados interno. |
Tipos de sincronização de datasets
Existem três tipos de sincronização com datasets:
...
| Nota | ||
|---|---|---|
| ||
Para que a sincronização de datasets ocorra corretamente, é necessário que a chave do banco seja configurada antes da sincronização para que não duplique os resultados. Essa configuração pode ser feita via tela no Painel de controle, selecionar a opção Plataforma ❙ Datasets > Escolher o dataset a ser sincronizado > Editar dataset > Tabela > Configurar > Campo chave para a tabela. Ou via código passando o setKey na function defineStructure. |
Existem três tipos de sincronização com datasets:
- Sincronização Comum: Este tipo de sincronização pode ser feita com qualquer dataset já implementado na plataforma. Neste modelo Sincronização Comum: Este tipo de sincronização pode ser feita com qualquer dataset já implementado na plataforma. Neste modelo de sincronização toda vez que a tarefa agendada de sincronização de datasets for executada será criada uma nova tabela e todos os registros retornados pelo método createDataset serão copiados para esta nova tabela. A tabela anterior será removida do banco. Esse modelo não é recomendado para datasets que retornam muitos registros.
- Sincronização Jornalizada: Este tipo de sincronização permite a atualização e cópia incremental de registros de acordo com o retorno do método onSync do dataset. Através do método defineScructure defineStructure é possível definir de forma mais detalhada quais são os campos da tabela bem como seus tipos. Também é possível criar índices e uma chave principal para obter ainda mais performance durante as consultas aos dados do dataset. No método OnSync é possível determinar quais são as linhas novas a serem adicionadas na tabela como na sincronização comum. Com os métodos updateRow e deleteRow através da configuração da chave é possível atualizar registros já existentes bem como eliminar registros. Esse modelo é o recomendado para situações em que há uma grande quantidade de dados.
Sincronização mobile: Este modelo de sincronização pode ser utilizado com qualquer dataset, seja ele sincronizado no servidor ou não, e permite a cópia local dos registros de um dataset em um dispositivo mobile que sincronize de forma offline com o fluiga plataforma. Os Os prazos de sincronização são configurados no aplicativo fluig Mobile.
Nota title Atenção Novos dados criados em dispositivos móveis, quando utilizando o modo offline, só estarão disponíveis para consulta em outros formulários depois que o aplicativo móvel passar por um processo de sincronização com o servidor do fluigda plataforma. Para entender mais sobre este processo, acesse nesta página o passo Configurando sincronização de datasets.
Desenvolvendo um dataset com sincronização jornalizada
...
Definindo a estrutura do dataset
Para definir a estrutura de um dataset jornalizado é necessário definir a estrutura fixa da tabela no código do dataset. Para isso no código do dataset deverá ser criado o método defineScructure defineStructure.
Exclusivamente dentro desta função estão disponíveis os seguintes métodos para definição da tabela:
| Retorno | Método | Descrição |
|---|---|
| AddColumn | AddColumn(String field, DatasetFieldType type)Cria um campo na tabela com o nome e tipo informados. O nome sempre deve ser informado em caracteres maiúsculos. O tipo de campo pode ser omitido e neste caso o campo será criado com o tipo String. Os tipos disponíveis são: DatasetFieldType.NUMBER DatasetFieldType.DATE DatasetFieldType.BOOLEANDatasetFieldType.STRINGDatasetFieldType.TEXT |
| setKey | setKey(Object[] fields) Determina quais são os campos chaves para o dataset. No banco de dados será criado um índice utilizando os campos informados neste método. Esses campos serão utilizados na localização dos registros para atualização ou remoção das linhas através dos métodos updateRow e deleteRow. Importante informar apenas campos que foram previamente definidos com a função addColumn. Devem ser informados em caracteres maiúsculos. |
| addIndex | addIndex(Object[] fields) Permite adicionar mais índices para obtenção de maior performance nas consultas do dataset. Devem ser informados em caracteres maiúsculos. |
Exemplo:
| Nota |
|---|
Quando um campo é definido como chave (setKey) o mesmo é definido automaticamente como índice. Neste caso, o campo não poderá ser utilizado para criação de um índice único, entretanto é permitido utilizar em um índice composto. No exemplo abaixo o campo 'CE_CODIGO' foi configurado como chave, portanto não pode ser utilizado como índice único 'addIndex("CE_CODIGO")'. Não há impedimento, porém, se usar em um índice composto, como está sendo utilizado no exemplo 'addIndex([ "CE_CODIGO", "CE_LOJA", "CE_NUMTIT" ])'. |
Exemplo:
| Bloco de código | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
function defineStructure() {
addColumn("CE_CODIGO", DatasetFieldType.NUMBER); | ||||||||
| Bloco de código | ||||||||
| ||||||||
function defineStructure() { addColumn("CE_CODIGO", DatasetFieldType.NUMBER); addColumn("CE_LOJA"); addColumn("CE_NUMTIT", DatasetFieldType.NUMBER); addColumn("CE_PARCELA"); addColumn("CE_PEFIXO"); addColumn("CE_TIPOLOJA"); addColumn("CE_VALORNUMTIT", DatasetFieldType.NUMBER); addColumn("CE_INSSPARCELA"); addColumn("CE_ISSPEFIXO"); addColumn("CE_IRRFTIPO"); addColumn("DTCE_TITULOVALOR", DatasetFieldType.DATENUMBER); addColumn("CE_PISINSS"); addColumn("CE_COFINSISS"); addColumn("LOGICO"CE_IRRF"); addColumn("DT_TITULO", DatasetFieldType.DATE); addColumn("CE_PIS"); addColumn("CE_COFINS"); addColumn("LOGICO", DatasetFieldType.BOOLEAN); setKey([ "CE_CODIGO", "CE_NUMTIT" ]); addIndex([ "CE_CODIGO" ]); addIndex([ "CE_CODIGO", "CE_LOJA", "CE_NUMTIT" ]); } |
| Nota | ||
|---|---|---|
| ||
|
Sincronização de informações
Para a transferência de dados do dataset para a tabela, deverá ser definida a função onSync que será chamado à chamada a cada execução da tarefa agendada.
Para que a sincronização aconteça deve ser criada uma tarefa no 'Plataforma ❙ Agendador de tarefas' do fluig com com o tipo 'Sincronização de dataset', selecionando qual dataset deverá ser sincronizado e em que período.
...
| Bloco de código | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
function onSync(lastSyncDate) {
var dataset = DatasetBuilder.newDataset();
var integracao = ServiceManager.getService('FLUIG3');
var serviceLocator = integracao
.instantiate('pkgWkfSolicPagamento.FLUIGLocator');
var service = serviceLocator.getFLUIGSOAP();
var cdEmp = 1; // código empresa pagadora
var cdFilial = 0; // todas as filiais
var cdTitulo = 0; // todos os titulos
var cdPrefixo = ""
var cnpj = 0; // cnpj fornecedor
var codForn = 0; // cod universal para todos os fornecedores
var lojaForn = 0; // loja fornecedor
// Invocando o servico passando a data da ultima sincronização com oa fluigplataforma.
// O webservice foi preparado para trazer apenas os dados desde a ultima
// sincronização.
var retorno = service.CONSPAG(cdEmp, cdFilial, cdTitulo, cdPrefixo, cnpj,
codForn.toString(), lojaForn.toString(), lastSyncDate);
var arrayListaTitulo = retorno.getLISTACPAG();
for (var i = 0; i < arrayListaTitulo.length; i++) {
var r = arrayListaTitulo[i];
if (r.getCE_TIPO() == "ADD") {
newDatasetdataset.addRow(new Array(r.getCE_CODIGO(), r.getCE_LOJA(), r
.getCE_NUMTIT(), r.getCE_PARCELA(), r.getCE_PEFIXO(), r
.getCE_TIPO(), r.getCE_VALOR(), r.getCE_INSS(), r
.getCE_ISS(), r.getCE_IRRF(), new java.util.Date(r.getDT_TITULO()), r
.getCE_PIS(), r.getCE_COFINS()));
} else if (r.getCE_TIPO() == "MOD") {
newDatasetdataset.updateRow(new Array(r.getCE_CODIGO(), r.getCE_LOJA(), r
.getCE_NUMTIT(), r.getCE_PARCELA(), r.getCE_PEFIXO(), r
.getCE_TIPO(), r.getCE_VALOR(), r.getCE_INSS(), r
.getCE_ISS(), r.getCE_IRRF(), new java.util.Date(r.getDT_TITULO()), r
.getCE_PIS(), r.getCE_COFINS()));
} else if (r.getCE_TIPO() == "DEL") {
newDatasetdataset.deleteRow(new Array(r.getCE_CODIGO(), r.getCE_LOJA(), r
.getCE_NUMTIT(), r.getCE_PARCELA(), r.getCE_PEFIXO(), r
.getCE_TIPO(), r.getCE_VALOR(), r.getCE_INSS(), r
.getCE_ISS(), r.getCE_IRRF(), new java.util.Date(r.getDT_TITULO()), r
.getCE_PIS(), r.getCE_COFINS()));
} else {
// Estado do registro é desconhecido no cache
newDatasetdataset.addOrUpdateRow(new Array(r.getCE_CODIGO(), r.getCE_LOJA(), r
.getCE_NUMTIT(), r.getCE_PARCELA(), r.getCE_PEFIXO(), r
.getCE_TIPO(), r.getCE_VALOR(), r.getCE_INSS(), r
.getCE_ISS(), r.getCE_IRRF(), new java.util.Date(r.getDT_TITULO()), r
.getCE_PIS(), r.getCE_COFINS()));
}
}
return dataset;
} |
Como funciona a sincronização das informações
Quando for necessário salvar no banco os dados do código, o corpo do método deve ser preenchido como abaixo.
| Bloco de código | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
function onSync(lastSyncDate) {
var dataset = DatasetBuilder.newDataset();
dataset.addRow(new Array(2256, "SÃO PAULO", 1058, "6", "ESPORTE"));
dataset.addRow(new Array(1874, "RECIFE", 1258, "1247690", "2", "CALÇADOS"));
dataset.addRow(new Array(1205, "RIO DE JANEIRO", 2594, "10", "MOVEIS"));
dataset.addRow(new Array(985, "FLORIANOPOLIS", 2269, "10", , "ELETRONICOS"));
return dataset;
} |
Como funciona a sincronização das informações
A forma como os dados são inseridos na base de dados é gerida pela plataforma TOTVS Fluig e desta forma o momento em que os registros são inseridos, editados ou excluídos no código do dataset, não é exatamente o mesmo momento A forma como os dados são inseridos na base de dados é gerida pelo fluig e desta forma o momento em que os registros são inseridos, editados ou excluídos no código do dataset, não é exatamente o mesmo momento em que, na prática, essas operações serão realizadas. Com isso, a importância em saber como funciona a sincronização e gravação de informações do dataset para tabelas de banco de dados é de utilidade geral.
Ao executar os métodos createDataset ou OnSync nas tarefas de sincronização o fluig a plataforma irá montar inicialmente em memória quatro coleções de registros que serão alimentadas de acordo com o comando utilizado pelo desenvolvedor.
...
Com as coleções montadas, a ordem que o fluig a plataforma utiliza para fazer a efetivação no banco é a seguinte.
...
Isso é necessário para que as alterações e efetivações de registros no banco sejam gerenciadas pelo fluig, afim de garantir melhor performance e obter um tempo reduzido na sincronização de informações.
Cache de dados no mobile
pela plataforma, afim de garantir melhor performance e obter um tempo reduzido na sincronização de informações.
Cache de dados no mobile
Quando se tem em mente um dispositivo móvel, imediatamente surge a questão do espaço ocupado por uma aplicação. A função onMobileSync é chamada apenas durante a atualização de um dataset offline já existente.
Este método serve para que os dados já sincronizados através do método onSync sejam ainda mais restritos adicionando uma nova constraint, por exemplo, ou definindo que somente algumas das colunas do dataset estejam disponíveis offline no dispositivo, evitando uso desnecessário de armazenamento.
Quando o aplicativo realiza a primeira sincronização, ao fazer o carregamento inicial dos dados, esta função não será executada.
Quando se tem em mente um dispositivo móvel, imediatamente surge a questão do espaço ocupado por uma aplicação. A função onMobileSync é chamada apenas durante a atualização de um dataset offline já existente. Esta função recebe o usuário autenticado no dispositivo como parâmetro e retorna todos os campos.
Quando o aplicativo realiza a primeira sincronização, ao fazer o carregamento inicial dos dados, está função não será executada.
deve retornar um objeto contendo as colunas a salvar, filtros e ordenação específicos para a Sincronização Mobile, conforme exemplo abaixo. Lembre-se de que todas as colunas informadas no código devem estar em caracteres maiúsculos.
...
| Bloco de código | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
function onMobileSync(user) {
var sortingFieldssortFields = new Array();
var constraintTitulo1 = DatasetFactory.createConstraint('CE_CODIGO',
'1', '1', ConstraintType.MUST);
var constraints = new Array(constraintTitulo1);
var colunastitulo = new Array('CE_CODIGO', 'CE_LOJA', 'CE_NUMTIT', 'CE_PARCELA',
'CE_PARCELA');
var result = {
'fields' : colunastitulo,
'constraints' : constraints,
'sortingFieldssortFields' : sortingFieldssortFields
};
return result;
} |
Acessando um Dataset com
...
sincronização
...
O acesso a datasets sincronizados, seja ele jornalizado ou não permance , permanece exatamente igual ao acesso de qualquer dataset, não sendo necessário passar nenhum parâmetro extra.
Configurando a sincronização de
...
datasets
...
A partir da atualização 1.6.2 o Painel de controle disponibiliza a opção Datasets, com uma No painel de controle, aba Gerais, clique sobre Datasets. Acessando essa tela, temos uma listagem de todos os datasets cadastrados no fluigna plataforma. Nessa tela é possível:
- Ligar ou desligar a sincronização de datasets em tabelas do servidor fluig.
- Ligar o ou desligar cache de informações de datasets em dispositivos mobile.
- Editar agendamentos para os datasets sincronizados.
- Consultar o dataset - consulta do código fonte do dataset.
- Consultar os dados do dataset
- Apagar todos os dados - Permite apagar os dados sincronizados para reiniciar a sincronização.

Configurando comportamento de acesso a datasets em dispositivos mobile
Clicando no lápis ao lado do valor da coluna "Offline mobile" é possível definir como será o comportamento do dispositivo mobile para realização do cache de informações bem como o acesso a essas informações de acordo com o estado do dispositivo.

Nesta tela temos as seguintes opções :
- Utilizar cache em dispositivos móveis: Define se o dataset terá ou não cache em dispositivos móveis.
- Tempo de expiração do cache mobile: Determina o período em que o cache será considerado válido desde a ultima sincronização de dispositivo.
- Não utilizar cache quando o dispositivo móvel estive online: Determina se o dispositivo consultará os dados do cache do dataset mesmo que o dispositivo esteja online através de redes wifi ou 3g/4g.
Utilize os botão salvar para confirmar as alterações.
Configurando sincronização de dados para o servidor do fluig
Clicando no lápis ao lado do valor da coluna "Sincronização" é possível definir que determinado dataset customizado irá sincronizar as linhas obtidas para dentro de uma tabela fluig.

A opção "Sincronizar com o servidor?" irá ativar o modo de sincronia de dados no servidor.
| Nota |
|---|
Ao desligar a sincronização de um dataset que estava sendo sincronizado e jornalizado lembre-se que as tabela que abrigada os dados e as tarefas de sincronização serão removidas e que por consequência todos os dados sincronizados até aquele momento serão perdidos. Com a sincronização desligada os dados que serão listados para este dataset são os dados obtidos pelo método createDataset. |
Editando agendamentos
Após definir que determinado dataset é sincronizado no servidor do fluig deverá ser agendada pelo menos uma execução da tarefa de sincronia de datasets para isso será necessário acessar o menu lateral ao lado da coluna ultima sincronização e escolher a opção "Editar Agendamentos" .

Nesta tela deverão ser preenchidos obrigatoriamente os seguintes campos :
- Descrição: Descrição obrigatória que irá identificar a tarefa na lista de tarefa agendadas.
- Tipo: Tipo da tarefa (o valor sincronização de datasets virá selecionado por padrão).
- Dataset: O dataset que será sincronizado (o dataset selecionado na tela anterior virá selecionado por padrão) .
As outras informações se referem a frequência e horário de execução da tarefa e segue o mesmo padrão dos outros tipos de tarefa agendada existentes no fluig.
Consultando dataset
Clicando sobre a lupa da coluna Opções referente ao dataset , ao lado da coluna "próxima sincronização", será possível consultar os resultados pertencente a consulta no banco de dados do fluig.

Exibir código do dataset
Este recurso é apenas um facilitador para o administrador verificar rapidamente o código do dataset. É importante o administrador do fluig se certificar se os métodos onSync, defineStructure, createDataset e onSyncmobile estão implementadas para que ele possa decidir se liga ou desliga a geração de cache e sincronização de informações. Esta função pode ser acessada através da coluna Opções, ao lado da coluna "próxima sincronização" deve-se escolher a opção "Exibir código" .

Apagar os dados
Essa opção permite ao administrador remover a tabela que contem os dados sincronizados com o servidor. Importante notar que os dados não serão apagados imediatamente após a confirmação da mensagem e sim na próxima execução da tarefa de sincronização. A próxima tarefa de sincronização criará uma nova tabela gravando os dados daquela execução. A tabela que abrigava os dados antes da ordem de eliminação de dados será removida junto com seus registros.
- a sincronização.
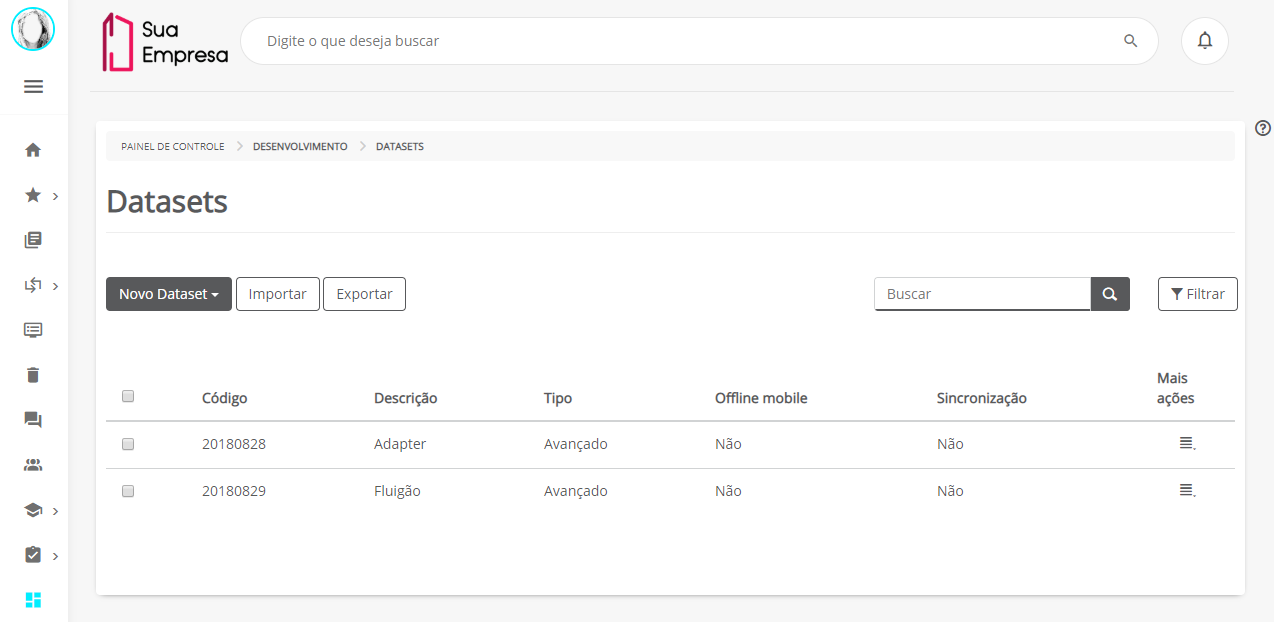
Figura 3 - Tela de dataset na atualização 1.6.5
Configurando comportamento de acesso a datasets em dispositivos mobile
É possível definir como será o comportamento do dispositivo mobile para realização do cache de informações, bem como o acesso a essas informações de acordo com o estado do dispositivo. Para isso, acione o link da coluna Offline mobile.
Figura 4 - Tela de Comportamento Mobile do dataset
Nesta tela temos as seguintes opções:
- Utilizar cache em dispositivos móveis: Define se o dataset terá ou não cache em dispositivos móveis.
- Tempo de expiração do cache mobile: Determina o período em que o cache será considerado válido desde a ultima sincronização de dispositivo.
- Não utilizar cache quando o dispositivo móvel estive online: Determina se o dispositivo consultará os dados do cache do dataset mesmo que o dispositivo esteja online através de redes wifi ou 3g/4g.
Utilize os botão salvar para confirmar as alterações.
Configurando sincronização de dados para o servidor da plataforma
Para definir que determinado dataset irá sincronizar as linhas obtidas para dentro de uma tabela da plataforma, é preciso clicar no link da coluna Sincronização, que abre a tela abaixo.
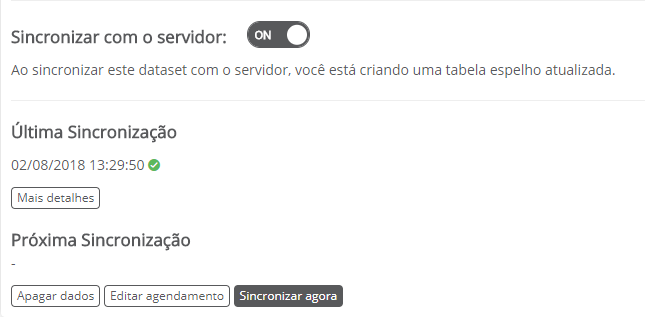
Figura 5 - Tela de Sincronização do dataset com o servidor
A opção Sincronizar com o servidor? irá ativar o modo de sincronia de dados no servidor.
| Nota |
|---|
Ao desligar a sincronização de um dataset que estava sendo sincronizado e jornalizado, lembre-se que as tabelas que abrigam os dados e as tarefas de sincronização serão removidas e que, por consequência, todos os dados sincronizados até aquele momento serão perdidos. Com a sincronização desligada, os dados que serão listados para este dataset são os dados obtidos pelo método createDataset. |
Apagar dados
Essa opção permite ao administrador remover a tabela que contém os dados sincronizados com o servidor. É importante notar que os dados não serão apagados imediatamente após a confirmação da mensagem, e sim, na próxima execução da tarefa de sincronização. A próxima tarefa de sincronização criará uma nova tabela gravando os dados daquela execução. A tabela que abrigava os dados antes da ordem de eliminação de dados será removida junto com seus registros.
Para apagar os dados, é preciso acionar o link da coluna Sincronização, que abre a tela de Sincronização (Figura 5), e então acionar a opção Apagar dados.
Editar agendamentos
Após definir que determinado dataset é sincronizado no servidor da plataforma, é preciso agendar pelo menos uma execução da tarefa de sincronia do dataset. Para acessar essa opção, é preciso acionar o link da coluna Sincronização, que abre a tela de Sincronização (Figura 5), e acionar a opção Editar agendamento.
Figura 6 - Tela de configuração do agendamento da sincronização
Nesta tela deverão ser preenchidos obrigatoriamente os seguintes campos:
- Descrição: Descrição obrigatória que irá identificar a tarefa na lista de tarefa agendadas.
- Tipo: Tipo da tarefa (o valor sincronização de datasets virá selecionado por padrão).
- Dataset: O dataset que será sincronizado (o dataset selecionado na tela anterior virá selecionado por padrão) .
As outras informações se referem a frequência e horário de execução da tarefa e segue o mesmo padrão dos outros tipos de tarefa agendada existentes. Para mais informações, consulte a documentação de usuário do Plataforma ❙ Agendador de tarefas.
Consultando dataset
Essa opção possibilita a consulta dos resultados do dataset no banco de dados da plataforma. Qualquer tipo de dataset pode ser consultado, mesmo aqueles que não tenham sincronização.
Para realizar a consulta, acione o ícone ![]() presente na coluna Mais ações e, em seguida, a opção Consultar.
presente na coluna Mais ações e, em seguida, a opção Consultar.
Figura 7 - Consulta aos dados do dataset
...
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas