Histórico da Página
Um dos pontos importantes sobre o conceito de observabilidade, dentro do contexto de sistemas e tecnologia, traduz-se em monitorar itens constantes que impactam no funcionamento de sistemas. Em um servidor, itens como CPU, memória e disco são constantes (sempre existem, independente do sistema operacional, programas instalados, etc); mas seus valores são variáveis que podem afetar o funcionamento de uma aplicação (por exemplo, alto consumo de CPU pode deixar um sistema lento, ou até mesmo interromper seu funcionamento).
As ferramentas descritas a seguir auxiliam no processo de monitoramento destes itens, e você também poderá importar um dashboardpara lhe auxiliar no monitoramento.
| Índice | ||||
|---|---|---|---|---|
|
| Informações | ||
|---|---|---|
| ||
Nesta página, você encontrará algumas ferramentas que podem ser utilizadas para o monitoramento de seu ambiente Protheus. As configurações aqui descritas pretendem facilitar a implantação do monitoramento; porém, não há impeditivos para que você configure seus dashboards de maneira diferente. Certifique-se apenas de que as informações coletadas agregarão valor àanálise de seu ambiente e não impactarão nofuncionamento da aplicação. Links relevantes InfluxDB • Instalação do InfluxDB • Criando um token do InfluxDB • Linguagem Flux • Primeiros passos com o Flux • Telegraf • Pilha TICK (TICK Stack) • Instalação do Telegraf • Primeiros passos com Telegraf • Criando um token para o InfluxDB • Grafana • Instalação do Grafana • Dashboard (Grafana) de observabilidade para ambientes Protheus |

InfluxDB
O InfluxDB é um banco de dados não relacional, que armazena as informações em formato de série temporal. A plataforma foi desenvolvida para coletar, armazenar, processar e visualizar métricas e eventos, e, dentre seus possíveis usos, é utilizada para armazenar os dados do sistema operacional e da aplicação, sendo possível consultar estes dados posteriormente por meio do Grafana. Como outros bancos de dados, não é necessário realizar a instalação de múltiplas instâncias do InfluxDB; ou seja, é possível instalá-lo em apenas uma máquina e configurar os serviços para apontarem para o mesmo.
Instale o InfluxDB por este link.
| Dica | ||
|---|---|---|
| ||
| Para realizar consultas no banco de dados InfluxDB, é utilizada a linguagem Flux. Você pode ler a documentação sobre a linguagem Flux ou conferir o guia para primeiros passos com o Flux. |
| Expandir | ||
|---|---|---|
| ||
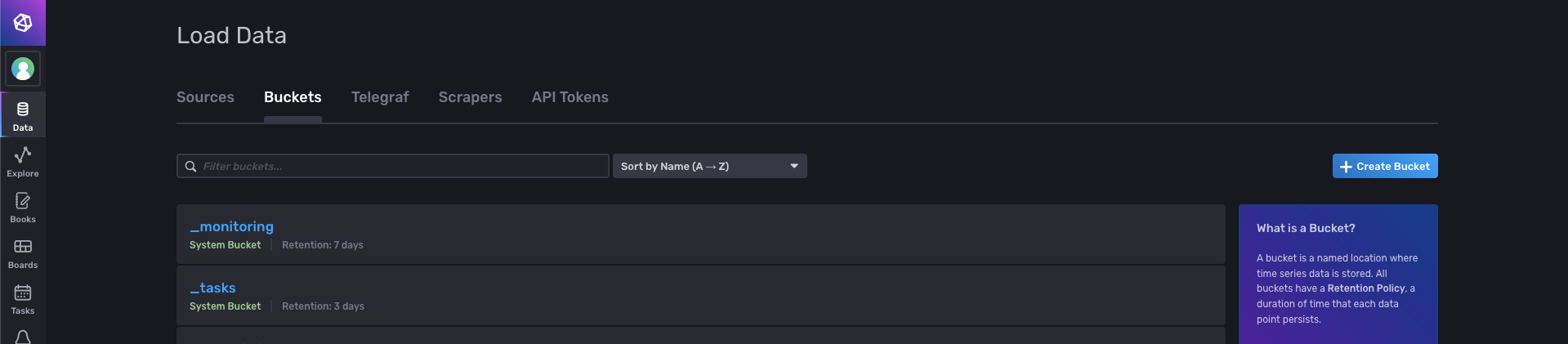
Após instalar o InfluxDB, será necessário: ♦ Criar uma nova bucket; ♦ Gerar um token para o coletor do Telegraf. Criando uma bucketPara criar uma nova bucket, acesse o endereço do InfluxDB pelo navegador, definido no momento de sua instalação. Em caso de dúvidas, verifique na documentação qual é o endereço e porta padrões. Na tela que carregará, clique, no menu lateral, em Data, e selecione a aba Bucket. Após isto, clique em +Create Bucket (canto superior direito) para adicionar uma nova bucket.
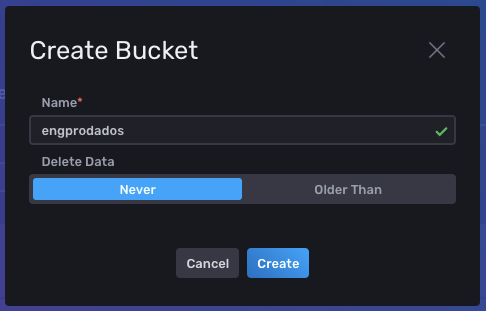
Atribua o nome da bucket que será criada no campo Name. Em seguida, clique em Create. Opcional: Você pode definir a deleção dos dados após determinado período (Older Than); mas não habilite esta opção para períodos curtos para poder ter uma análise mais precisa de seu ambiente. Lembre-se que os dados coletados podem ser utilizados para análise do consumo em momentos atípicos, onde seus recursos são consumidos de maneira diferente do normal.
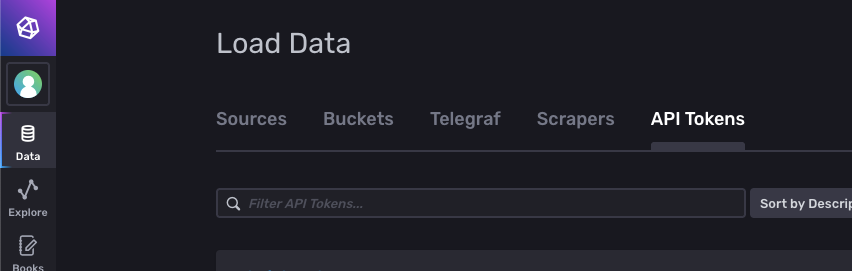
Gerando um token para o coletor do TelegrafApós criar a bucket, clique novamente em Data no menu lateral. Selecione a aba API Token.
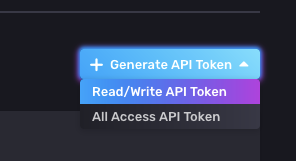
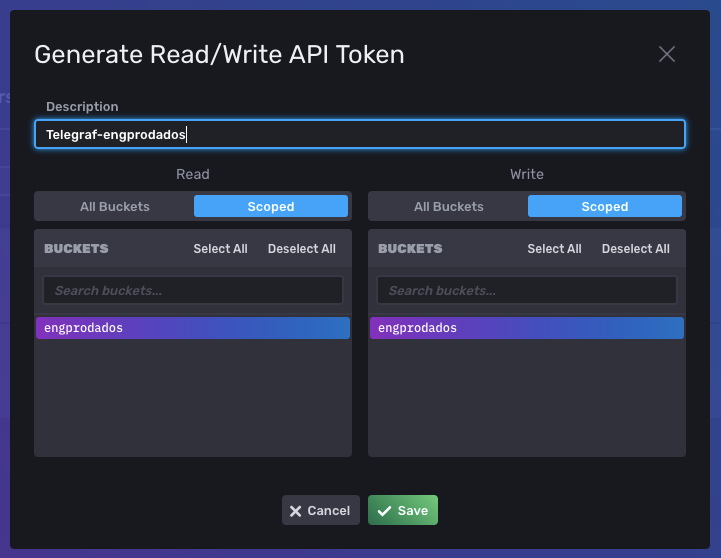
Clique em +Generate API Token e selecione Read/Write API Token.
Digite uma descrição para o token no campo Description. Em seguida, selecione o escopo de acesso. Neste caso, apenas a leitura e escrita da bucket criada anteriormente está sendo permitida. No lugar de "engprodados", estará o nome da bucket criada no passo anterior.
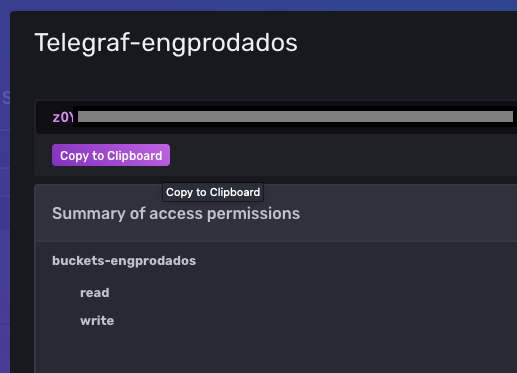
Copie o token gerado. Este será utilizado para configurar o telegraf dentro do arquivo telegraf.conf e no portal do Grafana.
Caso necessário, consulte a documentação oficial para verificar os passos de criação de token do InfluxDB. |

Telegraf
O Telegraf é um agente de servidor orientado por plug-in para coletar e reportar métricas, e é a primeira peça da pilha (stack) TICK. Esta stack é composta pelas ferramentas open source Telegraf, InfluxDB, Chronograf e Kapacitor que, quando integradas, podem lidar com massivas quantidades de informações de série temporal (time-stamp) para fins de análises de métricas.
O agente Telegraf possui plug-ins paracoletar uma variedade de métricas diretamente do sistema em que está sendo executado, bem como extrair métricas de APIs de terceiros. Para monitorar seu ambiente, o Telegraf será utilizado para coletar dados no sistema operacional e na aplicação; conforme os procedimentos nesta página, estes dados serão armazenados na base do InfluxDB e serão visualizados pelo Grafana.
Para instalar o Telegraf, acesse este link; para ver dicas sobre os primeiros passos com o telegraf, acesse este link. Também é possível executar o telegraf como um serviço do Windows.
| Expandir | |||||||
|---|---|---|---|---|---|---|---|
| |||||||
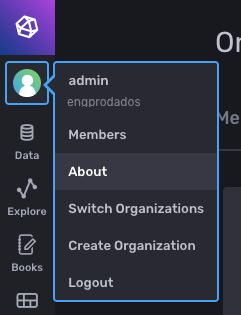
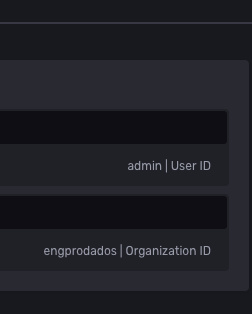
Seguindo o exemplo de instalação do Telegraf como serviço Windows, os parâmetros necessários serão editados para o funcionamento adequado do dashboard no Grafana. Nesta seção, você verá: ♦ Como editar o arquivo de configuração do Telegraf; ♦ Como conectar o Telegraf à base criada no InfluxDB. Acesse o caminho onde está o arquivo telegraf.conf padrão, (por exemplo, "C:\Program Files\InfluxData\telegraf\telegraf.conf") e substitua o conteúdo deste arquivo pelo do arquivo telegraf.conf disponibilizado no git. Após inserir o conteúdo, será necessário editar algumas chaves para se conectar a seu ambiente. Localize a chave token e insira o token criado previamente no InfluxDB, detalhado na seção anterior. Localiza as chaves bucket e organização e insira os valores correspondentes aos de seu ambiente InfluxDB, definidos durante a instalação (em caso de dúvidas, o nome da organização pode ser acessado em Menu do usuário > About. No canto direito será exibido o nome da organização).
Consulte também os primeiros passos com Telegraf. |
Grafana
O Grafana é uma ferramenta open source que permite que você consulte, visualize, e tenha alertas sobre as mais variadas métricas, com armazenamento possível em várias bases de dados diferentes; esta é uma das várias ferramentas disponíveis no mercado que realizam esta função.
| Informações | ||
|---|---|---|
| ||
O Grafana não é um coletor nem uma base de dados; é apenas uma ferramenta que apresenta os dados coletados por meio de outras ferramentas. Para a coleta foi utilizado o Telegraf, e para o armazenamento, o InfluxDB. Importante ressaltar que nesta página está demonstrada a configuração das três ferramentas. |
Consulte este link para realizar a instalação do Grafana. Após a instalação, será necessário instalar o plugin Clock no Grafana.
| Expandir | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
Após instalar o Grafana e o plugin Clock, será necessário: ♦ Configurar a origem dos dados (data source) que serão apresentados no Grafana; ♦ Configurar seu dashboard (nota: um dashboard foi criado pela Engenharia de Dados Protheus para facilitar a visualização dos dados, e este será importado; para configurar seu dashboard sem importar este, consulte a documentação do Grafana para maiores detalhes). Configurando o data sourceAcesse o endereço do serviço Grafana (definido na instalação; em caso de dúvidas, consulte a documentação) para visualizar o painel. Clique em Configuration > Data Sources no menu lateral esquerdo:
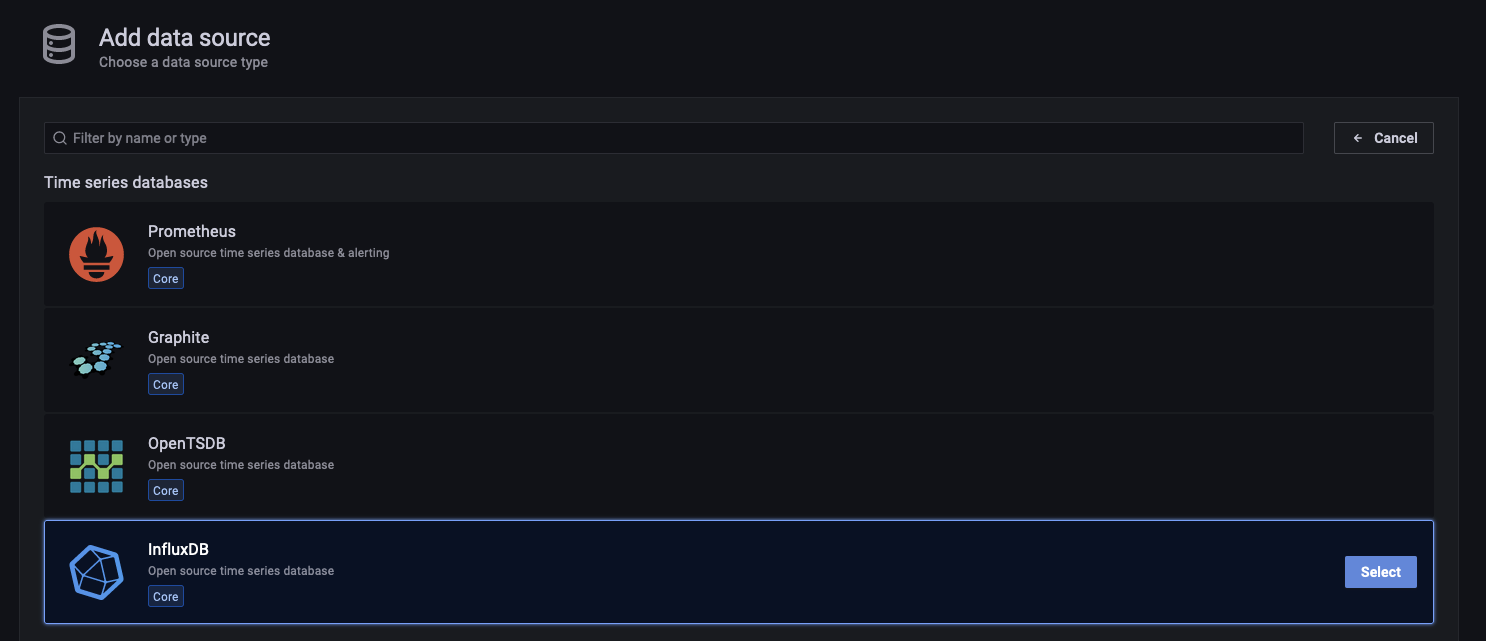
Em seguida, clique em Add data source, à direita:
Nas opções de databases, selecione InfluxDB:
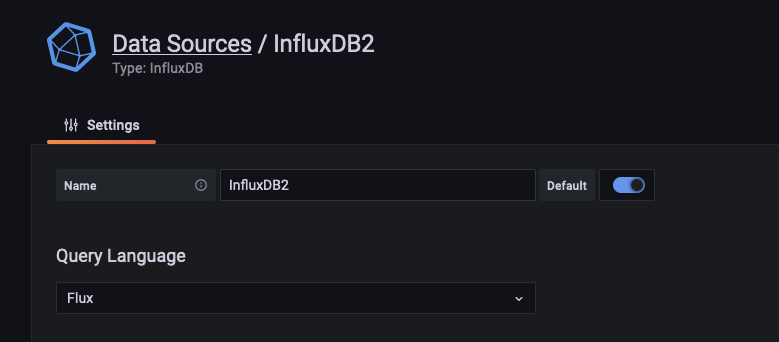
Em Name, defina um nome para o datasource (este nome será utilizado no dashboard), e em Query Language, selecione FLUX.
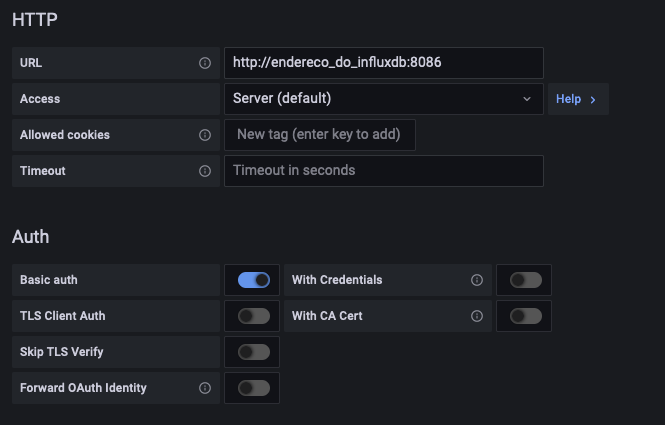
Na seção HTTP, defina, em URL, o endereço do InfluxDB (IP do servidor onde o InfluxDB está instalado e porta). Se a instalação do InfluxDB foi realizada conforme o padrão de instalação descrito no site da ferramenta, os parâmetros abaixo podem ser deixados da maneira sugerida pelo Grafana. Na seção Auth, caso a instalação tenha sido conforme o padrão, você pode definir as configurações conforme esta página. Caso contrário, será necessário consultar a documentação para a configuração de autenticação. Defina Basic Auth como habilitado, e coloque o User (usuário cadastrado no InfluxDB) e Password (senha de acesso ao InfluxDB). Em Custom HTTP Headers, inclua o header Authorization com o valor "Token <TOKEN_GERADO_NO_INFLUXDB>"
Na seção InfluxDB Details, defina:
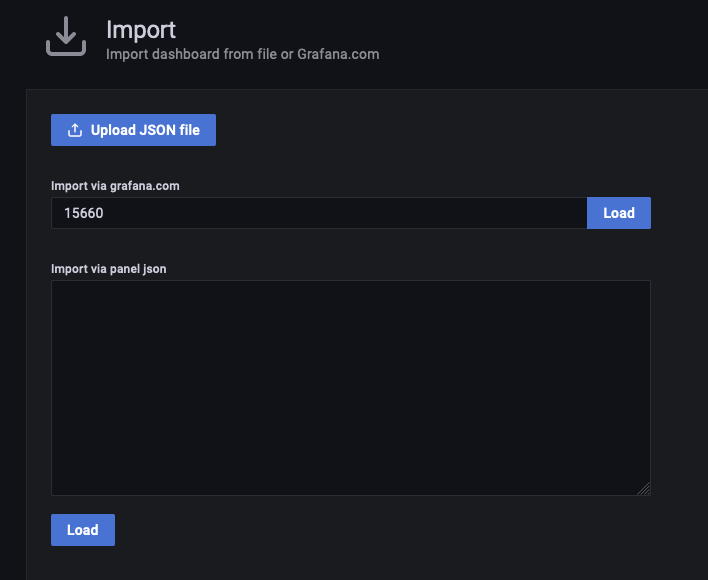
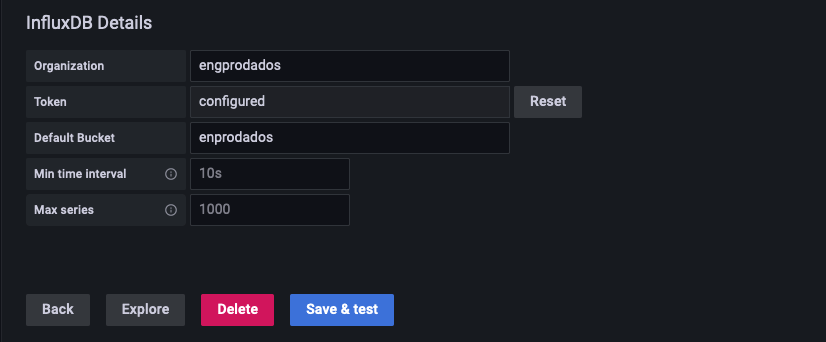 Após isto, clique em Save & Test. Importando o Dashboard do Grafana para ProtheusApós configurar os acessos, no menu lateral, clique em Import. 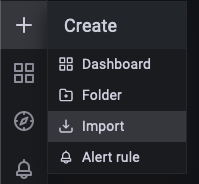 Insira o código 15660 no campo Import via grafana.com e, em seguida, clique em Load.
 As configurações serão carregadas; clique em Import. 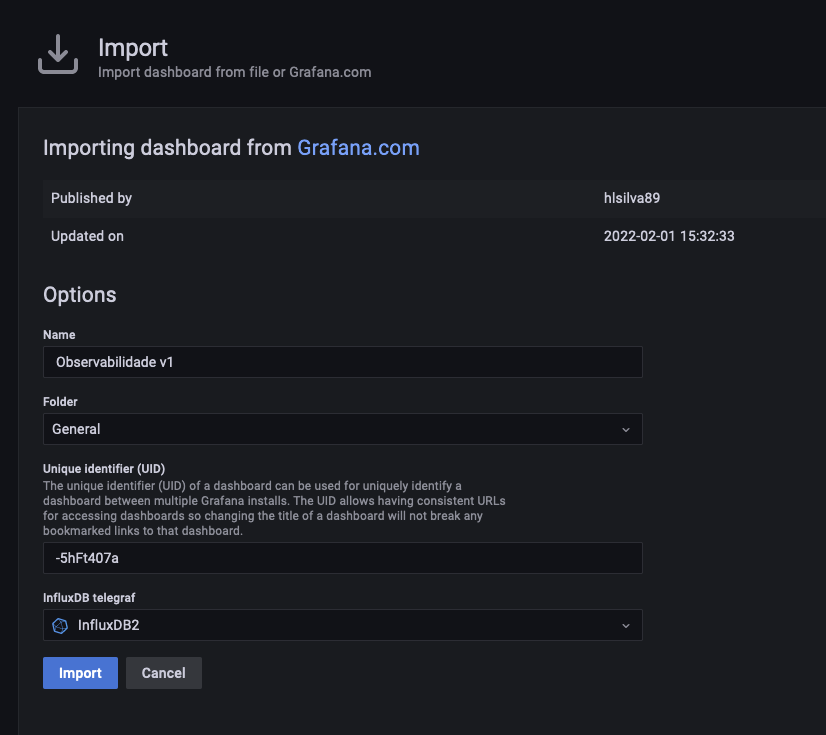 Na tela inicial selecione, em bucket, a bucket onde os dados do telegraf estão sendo armazenados; em instances, selecione a instância que deseja monitorar; e em services, selecione o serviço que deseja monitorar.
|


Com estas configurações, você poderá monitorar seu ambiente Protheus de maneira mais fácil. O print a seguir mostra o painel configurado conforme o descrito neste documento.

Simplificando no uso do Protheus
Aplicando a observabilidade do protheus para estudo de métricas.
CPU - Gerando o dia a dia do processamento do cliente
É preciso entender as métricas do cliente, para que ele saiba como é o consumo do Protheus utilizado por ele. Ou seja, é necessário entender o dia em que ele mais consome dados, o dia em que ele menos consome, o horário de pico do uso de dados e várias outras métricas, que vão ajudar a entender esse consumo de toda a arquitetura computacional, (CPU, memória e disco). Neste caso, a CPU é o principal item a ser analisado neste cenário.
Memória - Análise
Analisar a memória é entender o consumo de serviços, como o horário de pico do consumo, o horário em que esse consumo começa a reduzir, entender os insights para que ele saiba o que ocorre na máquina primária, para monitorar os dados e se planejar sobre o que será preciso comprar ou investir para ter uma estrutura cada vez melhor.
Ao monitorar as métricas durante o período de um ano, o cliente vai entender o que ele precisa para o futuro.
Afinal, o monitoramento ajuda a fazer um diagnóstico sobre possíveis problemas que possam surgir e ajuda a entender os cenários para possíveis atualizações e correções de erros.
Para entender tudo isso, basta monitorar o seu log, ativando o LOG Manager.
Ao observar melhor o LOG, é possível ter um histórico de toda a arquitetura, para criar uma baseline e saber quais foram os momentos do mês, ano e dias mais importantes em cada período analisado.
LOG - Coletar os LOGs
O Protheus gera muitas informações por ser um dos ERPs que mais geram logs para entender comportamentos.
Com ele, é possível criar um data lake, usando graylog ou kibana. Ou seja, é possível criar um log para entender os momentos de problemas do cliente, como situações de erros, analisando se o mesmo erro surge outras vezes, guardando um histórico de todos os dados monitorados, para fazer um fluxo de tudo o que é monitorado e entender a frequência de cada comportamento registrado.
Assim, ao customizar um cenário, é possível descobrir uma solução de maneira muito mais rápida. Coletar os logs ajuda também a entender e programar possíveis atualizações da arquitetura.
A customização é ponto importante de todo esse processo, porque o Protheus é adaptável às necessidades de cada cliente.
E se o cliente tiver o mundo da observabilidade implantado no ambiente dele, ao monitorar o primeiro ano de uso, ele vai entender quais serão seus objetivos e possíveis adaptações para o próximo ano.
Com isso, ele sabe se precisa de mais hardware ou mais consumo de arquitetura. É possível analisar se o cliente precisa estar em uma nuvem pública para sair do monolito do hardware físico.
E vale lembrar que o Protheus está homologado atualmente para funcionar nas 5 principais nuvens do mercado (a nuvem TOTVS e outras quatro nuvens públicas), garantindo um grande ecossistema em que o Protheus pode ser usado.
O que a engenharia do Protheus utilizou para entender o comportamento do Protheus foi a observabilidade, por meio do Grafana, e os próprios recursos das nuvens, como OCI.
Entre as atualizações 27 e 33, com a ajuda da observabilidade, foi possível chegar à métrica padrão de consumo de memória da aplicação. Foi preciso ficar três anos observando quanto estava sendo o consumo do Protheus, em testes de clientes betas e em ambientes internos.
O time do Protheus passou a fazer uma regressão linear para entender esse comportamento, observando as métricas de consumo de CPU, memória e disco.
Com esse levantamento foi possível repassar aos clientes informações mais precisas sobre o consumo de dados, que vão ajudar a reduzir custos e ajustar o crescimento da base de dados.
...
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas