Histórico da Página
...
| Expandir | ||
|---|---|---|
| ||
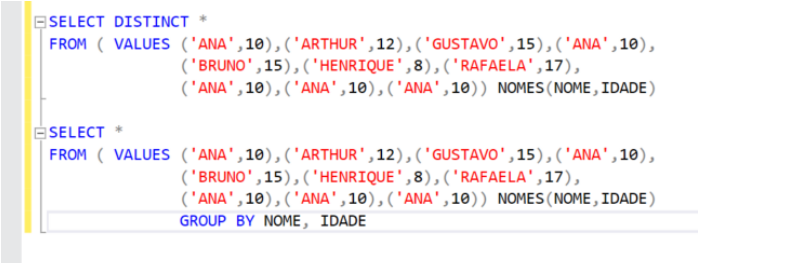
Não use Distinct, tente utilizar Group By no lugar. Sabemos que cada um tem seu propósito e dependendo da situação não poderemos substituir um pelo outro. Contudo se houver oportunidade de fazê-lo, tente aplicar, como por exemplo:
Obs.: Sempre analise o ‘plano de execução’ entre as duas abordagens, optando em adotar o item que gerou menor custo. |
| Expandir | ||
|---|---|---|
| ||
Análise o plano de execução estimado da consulta; O plano de execução é um ótimo aliado para avaliar as condições de performance em seus comandos, quando possível utilize até mesmo o plano de execução real para que receba a informação concretizada sobre suas consultas:
Obs.: O plano de execução estimado não consegue obter resultados de leitura em disco e demais recursos envolvidos na busca das informações do disco para apresentação na tela ao que o ‘plano de execução real’ assiste tais métricas. Outro ponto importante sobre o uso do ‘plano de execução estimado’ é que ele se baseia nas estatísticas da base de dados, caso elas estejam desatualizadas, teremos problemas na composição deste plano. |

| Expandir | ||
|---|---|---|
| ||
Utilize flags de tipo booleano ou inteiro (colunas deste tipo), o Oracle não possui este tipo, portanto, utilize o tipo numeric (0 ou 1); |
| Expandir | ||
|---|---|---|
| ||
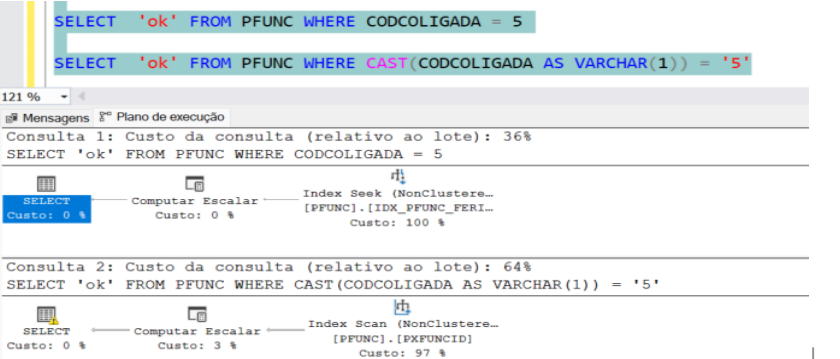
Evite utilizar conversões com UPPER, TO_CHAR e etc em cláusulas WHERE, esta operação faz com que o banco de dados naturalmente ignore a utilização dos índices automáticos criados para estas colunas, que tornariam a consulta bem mais rápida. Veja este exemplo: Observe a imagem abaixo, seria a mesma consulta que gera o mesmo resultado, mas com alguns pontos de atenção a serem observados no uso de funções na cláusula where:
Podemos ver que nativamente o índice ‘não clusterizado’ foi escolhido na primeira busca pois a coluna estava associada a este índice, com essa decisão ele conseguiu fazer uma busca ‘seek’ que é mais direcional para encontrar o valor necessário. Na segunda consulta o usuário decidiu fazer uma conversão do tipo de dados. Neste momento o sgbd* decidiu utilizar o índice da chave primária para buscar toda a tabela e fazer um ‘scan’ até encontrar o valor necessário. Conclusão: Avalie muito se é possível não inserir expressões com funções as quais retiram uma busca ‘seek’ num índice ‘não clusterizado’ na coluna presente dentro da cláusula where. Pesquise algo referente a consultas NoSarg e Sarg (termo Search Argument Table). |
| Expandir | ||
|---|---|---|
| ||
Não utilize HAVING para filtrar dados, caso necessite filtrar dados em um agrupamento de informações, prefira sempre realizar esta operação na cláusula WHERE ao invés do HAVING, por questões de performance, a não ser que seja necessário realizar algum filtro utilizando realmente as operações de agregação;
|
| Expandir | ||
|---|---|---|
| ||
Uso do ‘SET NOCOUNT ON’, consegue visualizar ganhos? Em muitos casos um comando executado por ‘stored procedure’ pode gerar grande fluxo de informações na rede e que talvez não ser usado para qualquer regra. Durante ‘updates’, por exemplo, na maioria dos casos não capturamos o valor das linhas afetadas, sendo gerado um fluxo de informações desnecessárias. Esse recurso se torna valioso quando abrimos transações demoradas se dispensamos o retorno de quantas linhas foram afetadas após o ‘commit’ * sgbd = Gerenciamento de Banco de Dados (SGBD) – do inglês Data Base Management System (DBMS) |
Mais informações sobre consultas SQL's podem ser acessadas em https://tdn.totvs.com/display/LRM/Trabalhando+com+Consultas+SQL
...
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas