Histórico da Página
Obs: Estas recomendações são apenas um direcionamento básico para uma boa operação do servidor de banco de dados e não deve ser considerado como único padrão de avaliação, monitoração, e configuração do banco de dados que deve ser realizado por o DBA responsável.
1 - COLLATION
- No padrão CorporeRM o Collation deverá ser definido com SQL_Latin1_General_CP1_CI_AI, e a linguagem (Default Language) como US_ENGLISH ou ENGLISH para os logins RM e SYSDBA.
- Seguindo o padrão da TOTVS, na criação do banco Corpore deve-se utilizar o sort order 54, (DICTIONARY ORDER, CASE-INSENSITIVE, ACCENT-INSENSITIVE, FOR USE WHITH 1252 CHARACTER SET) lembramos que na instalação o default é o sort order 52. Para confirmar, realize a consulta no query sp_helpsort.
Nota: Os Logins RM e SYSDBA deveram ser criados, conforme script de Acerta Usuários: BD0016_SQL_Server_Acerta_Usuário
2. SERVER AUTHENTICATION
Verifique a autenticação que está sendo realizada para conexão do SQL.

Para isso, basta clicar com o botão direito no nome do servidor (Management Studio) e clicar em propriedades.
Na guia Security, na opção Server authentication, marque a opção SQL Server and Windows Authentication mode. A base de dados RM utiliza o usuário do banco de dados para realizar a autenticação do sistema, por este motivo, precisamos da autenticação do SQL para acessar o sistema. Verifique se o serviço vai reiniciar após confirmar esta opção.
3. PARÂMETROS
Partindo do pressuposto que a base vazia foi criada com o nome de Base_RM e o script de usuários também já foi executado na mesma, vamos conferir alguns parâmetros do banco:
Selecione o menu propriedades da base RM (Nesse menu estarão disponíveis todas as informações gerais da base de dados):
- General - Esta guia contém informações gerais da base, como data de criação, nome, tamanho, último backup, etc.
- Files – Contém os Databases files (a localização do arquivo mdf e ldf que contém os dados e o tamanho dos mesmos) onde podemos criar arquivos secundários apontando discos diferentes, que assim que esgotar o espaço do primeiro arquivo irá dar continuidade ao próximo.
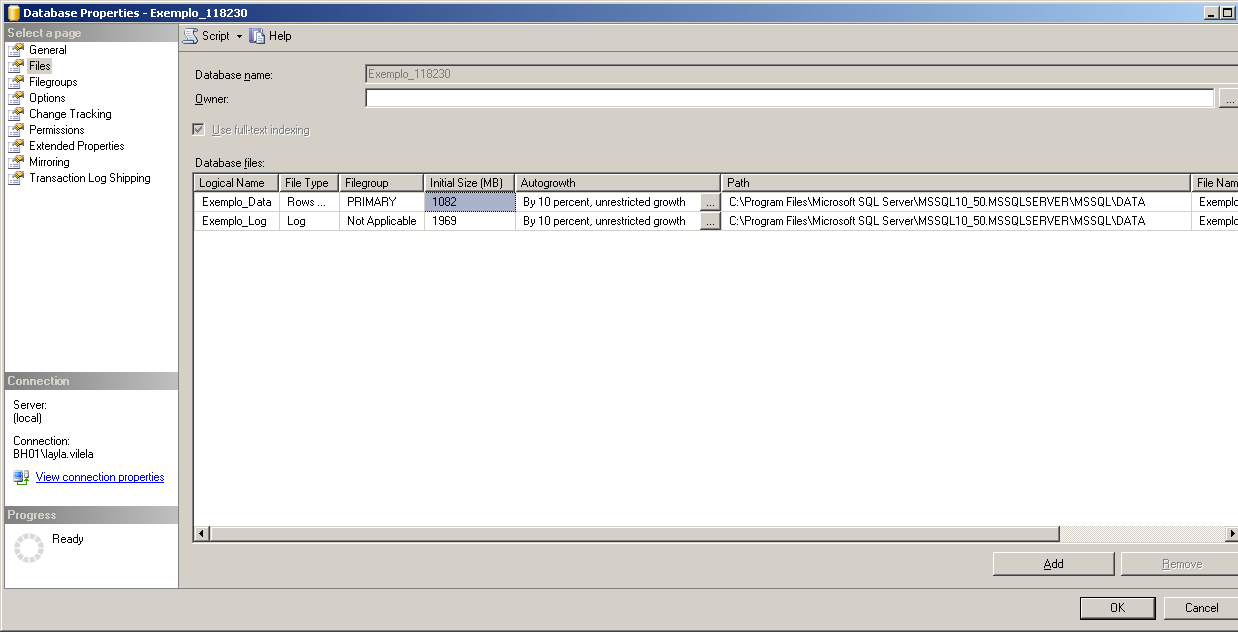
Sugerimos que seja parametrizado para o crescimento automático (Enable Autogrowth) e no File Growth utilizar o In Percent (10), já no Maximum File Size devemos ter muito critério ao marcar a opção de Unrestrict File Growth, apesar de recomendarmos, pois enquanto tiver espaço em disco e o banco necessitar ele irá expandir sem problemas, porém se o espaço estourar poderá danificar o banco de dados:

- Base.ldf - Contém o nome do file name, a localização do arquivo ldf que contém o log, e o tamanho do mesmo. Quanto à configuração, podemos nos basear nas configurações acima.
- Filegroupes – Os grupos de arquivos permitem que os arquivos de banco de dados e objetos sejam logicamente agrupados.
- Options – Solicitamos que marque somente o parâmetro:
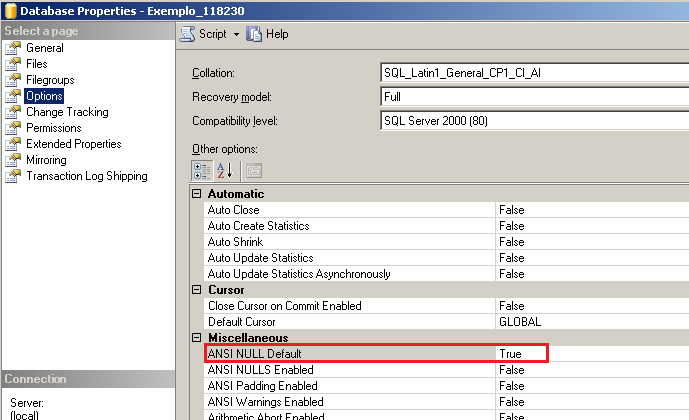
- ANSI NULL Default – Quando esta opção é setada, os tipos de dados ou colunas que não estão explicitamente definidas como NOT NULL durante a criação ou alteração da tabela irá permitir valores nulos.
Verificando os demais parâmetros:
- Auto Close – Quando esta opção está marcada, o banco criará overhead adicional associado com abertura e fechamento de arquivos do banco de dados, o que não recomendamos para bancos que estão constantemente em utilização.
- Auto Update Statistics – Configurada como True, as estatísticas de índice são automaticamente atualizadas, podendo gerar queda de performance.
- Auto Create Statistics – Configurada como True, as estatísticas de índice são automaticamente criadas, sempre que você criar um índice, o SQL Server cria um conjunto de estatísticas sobre os dados contidos dentro do índice. O otimizador de consulta utiliza essas estatísticas para determinar se ele deve ou não utilizar o índice para ajudar a processar a consulta. Devido a característica das aplicações da linha RM, pode ser benéfico para o desempenho de relatórios e outros itens customizados que eventualmente demandem filtros específicos que não são compreendidos por índices padrões do produto, bem como em melhorias de planos de execução ineficientes. Por padrão o backup de nossa base vazia, utilizada normalmente para implantação possui este parâmetro desmarcado para não gerar estatísticas em todas as tabelas. No entanto, esta é uma opção do banco de dados que poderá ser utilizada em cenários específicos de análise de desempenho mensurando o impacto, custo de manutenção e resultados obtidos com a utilização deste parâmetro como TRUE. A Microsoft recomenda a utilização deste parâmetro como TRUE por default.
- Auto Shrink – Caso esta opção esteja setada o banco, os arquivos de log “encolhem-se” automaticamente, reduzindo o espaço de disco rígido e isso pode degradar o desempenho, caso seja necessário encolher o banco, você poderá utilizar o comando DBCC SHRINKDATABAS.
- Quoted Identifiers – Marcando esta opção, os nomes de objetos dentro de aspas duplas não precisam obedecer à convecção para atribuição de nomes reservados ao SQL, como “date”, “primary”, sugerimos a não marcação deste parâmetro.
- Recursive Trigger – Se não for adequadamente implementada, a recursão pode levar a loop sem fim.
- Torn Page Detection – Este parâmetro marcado detecta se uma página está danificada, listando no event view, fica a critério do cliente marcar ou não esta opção, pois não influenciará no desempenho do banco.
: - Compatibility Level – Vide link: BD0025_SQL_Server_Parametrização_do_Nivel_de_Compatibilidade
4. MANUTENÇÃO:
- Mantenha a base de dados e o servidor de banco de dados de acordo com as recomendações do documento de portabilidade da TOTVS. O documento de portabilidade pode ser obtido através do portal do cliente, onde existirá um documento por versão (XX.XX) – (Portabilidades). Motivo: Diversos problemas podem ocorrer na conversão relacionada à insuficiência de recursos da instancia do banco de dados ou parâmetros do banco de dados fora do padrão homologado. O modelo padrão é a base vazia disponibilizada pela TOTVS, em caso de dúvidas a mesma pode ser verificada para comparação de parâmetros.
- Não executar scripts DML ou DDL diretamente na base de dados sem o aval da TOTVS. Scripts executados diretamente na base de dados podem alterar a estrutura e gerar inconsistências na base, o que no momento da conversão pode ser evidenciado ocasionando a necessidade de validação da base de dados. O processo de validação pode ser moroso e gerará custos para o cliente, visto ser um processo de consultoria de especialistas em Banco de dados.
- Efetuar a manutenção da base de dados, realizando a reindexação e ou reconstrução de índices e atualização de estatísticas além de monitorar o espaço para crescimentos dos arquivos de dados e arquivos de log do banco de dados. Verifique também a consistência física e lógica da base de dados. Estes procedimentos são de responsabilidade do DBA da empresa, caso não possua DBA a equipe de consultoria da TOTVS poderá ser acionada para esta avaliação. Disponibilizamos os scripts para reindex/rebuild de índices e atualização de estatísticas (SQL Server - Manutenção_Servidor). Os scripts são duas stored procedures a serem criadas na base. Abaixo orientações de execução das mesmas:
Exemplos de como executar a procedure Index_defrag2:
/** Executando com parâmetros defaults **/
execute RMIndexDefrag
/** Executando com opção de recalculo do Fill Factor **/
execute RMIndexDefrag @recalcfillfactor = 1
/** Executando sem output **/
execute RMIndexDefrag @debugmode = 0
Exemplo de como executar a procedure RMatualizaestatisticas:
Exec RMatualizaestatisticas
Recomendamos que o DBA avalie a periodicidade para execução destas procedures, caso não possua DBA, execute as mesmas na seguinte periodicidade:
- Index_defrag2 – Semanalmente}
- RMatualizaestatisticas - Diáriamente
5. RECOVERY MODEL:

O log do SQL Server poderá crescer mais ou menos a depender do recovery model escolhido.
O recovery model simple, irá logar as transações realizadas, porém ao escolher este nível de recuperação o SQL Server entende que sua tolerância para perda de dados não envolve recuperação point in time ou backups full e diferencial são suficientes. Desta forma, ao atingir um certo volume o SQL Server automaticamente realiza um checkpoint em background e confirma as transações pendentes no log para o arquivo de dados. Caso seu recovery esteja como simple e seu log esteja crescendo rapidamente e não retornando a um tamanho gerenciável existem algumas ações a serem realizadas:
- Checkpoints manuais
- Shrink file
Caso ainda assim, tenha dificuldade em reduzir o log, pode existir alguma configuração na instância relacionada a replicações realizadas no passado ou alguma outra configuração voltada a este cenário impactando o processo de checkpoint.
Caso esteja utilizando o recovery full, o responsável mais comum por realizar o processo de checkpoint sem a intervenção do DBA é o processo de backup do log de transação. Ao se realizar o backup, o processo de checkpoint é realizado de forma automática no momento deste backup, mantendo os arquivos de log em produção em tamanhos gerenciáveis. Para isso, é necessário escolher a periodicidade do backup de log conforme o seu negócio.
Caso o seu recovery model seja full e o processo de backup de log não esteja sendo realizado, este pode ser o problema relacionado ao crescimento dos arquivos.
Caso não seja o DBA da empresa, sugiro que alinhe estas informações com o mesmo para tomada de decisão.
6. IMPORTÂNCIA DA VERIFICAÇÃO DA INTEGRIDADE DA BASE DE DADOS
Seguem algumas dicas para evitar esse tipo de problema:
1. Faça a verificação diária da integridade da base antes de realizar os backups. Pode ser criado um plano de manutenção ou pode um job que executa o comando dbcc checkdb nas bases de dados;
2. O Recovery Model Full é requisitado em casos extremos, como o restore de páginas corrompidas, porém poderá acarretar em um alto consumo do disco;
| Informações |
|---|
O log do SQL Server poderá crescer mais ou menos a depender do recovery model escolhido. O recovery model simple, irá logar as transações realizadas, porém ao escolher este nível de recuperação o SQL Server entende que sua tolerância para perda de dados não envolve recuperação point in time ou backups full e diferencial são suficientes. Desta forma, ao atingir um certo volume o SQL Server automaticamente realiza um checkpoint em background e confirma as transações pendentes no log para o arquivo de dados. Caso seu recovery esteja como simple e seu log esteja crescendo rapidamente e não retornando a um tamanho gerenciável existem algumas ações a serem realizadas:
Caso ainda assim, tenha dificuldade em reduzir o log, pode existir alguma configuração na instância relacionada a replicações realizadas no passado ou alguma outra configuração voltada a este cenário impactando o processo de checkpoint. Caso esteja utilizando o recovery full, o responsável mais comum por realizar o processo de checkpoint sem a intervenção do DBA é o processo de backup do log de transação. Ao se realizar o backup, o processo de checkpoint é realizado de forma automática no momento deste backup, mantendo os arquivos de log em produção em tamanhos gerenciáveis. Para isso, é necessário escolher a periodicidade do backup de log conforme o seu negócio. Caso o seu recovery model seja full e o processo de backup de log não esteja sendo realizado, este pode ser o problema relacionado ao crescimento dos arquivos. Caso não seja o DBA da empresa, sugiro que alinhe estas informações com o mesmo para tomada de decisão. |
3.Verifique a integridade física dos dispositivos de armazenamento. Utilize softwares como o ScanDisk do Windows para avaliar possíveis problemas como bad sectors;
4. Realize verificações periódicas nas baterias dos no-breaks;
5. Faça testes de restauração dos backups para prevenir qualquer tipo de eventualidade. Exemplo: falhas de integridade, problemas na compactação, defeitos na mídia etc.
Sendo assim, a verificação da integridade da base de dados é tão importante quanto à realização do próprio backup. Não deixe de inserir essa verificação nas suas rotinas de manutenção.
Links Complementares:
Visão Geral
Import HTML Content
Conteúdo das Ferramentas
Tarefas