Índice
| Índice |
|---|
| maxLevel | 4 |
|---|
| outline | true |
|---|
| exclude | .*ndice |
|---|
| style | none |
|---|
|
...
As instruções a seguir completarão a instalação de um fluig Indexer em um cluster de servidores dedicados, continuando as instruções iniciadas na página Fluig Indexer em Servidor DedicadoServidor de indexação dedicado.
Na maioria dos cenários, uma máquina bem dimensionada executando o serviço de indexação é suficiente para atender as demandas de indexação e busca da plataforma.
...
| Bloco de código |
|---|
| language | bash |
|---|
| theme | Eclipse |
|---|
| title | zoo.cfg |
|---|
|
tickTime=2000
dataDir=C:/varzookeeper/lib/zookeeperdatadata
clientPort=2181
initLimit=5
syncLimit=2
server.1=<server1_address>:2888:3888
server.2=<server2_address>:2888:3888
server.3=<server3_address>:2888:3888 |
- tickTime: corresponde ao tempo em milisegundos entre cada tick, sendo que uma das validações para determinar se um nó está disponível é de dois ticks (similar ao ping para verificar se uma máquina é encontrada na rede). Se dois ticks consecutivos não obtiverem resposta, ocorre timeout e a máquina é considerada indisponível.
- dataDir: aponta o diretório onde serão armazenadas as informações referentes ao cluster. No início, este diretório deve estar vazio e com permissão de escrita pelo usuário que irá iniciar o ZooKeeper. O mapeamento deve ser feito sempre com o caracter '/', mesmo em ambientes windows.
- clientPort: corresponde à porta que será utilizada pelo Apache® Solr.
- initLimit: quantidade de tempo (em ticks) para que uma máquina com ZooKeeper se conecte e sincronize com a máquina que foi eleita líder. Neste caso, são 5 ticks com 2000 milisegundos cada, totalizando 10 segundos. Este valor pode ser incrementado sob demanda se a quantidade de informações gerenciadas pelo ZooKeeper for elevada.
- syncLimit: quantidade de tempo (em ticks) que uma máquina com ZooKeeper pode estar atrasada em relação à líder. Se uma máquina não conseguir sincronizar com a líder neste intervalo, ela será descartada do cluster.
- server.X: são os IDs e localização (endereço na rede interna) de todos os nós do cluster, e as portas nas quais eles comunicam-se entre si. O ID identifica cada nó do cluster, precisando ser referenciado em um arquivo de nome 'myid', dentro do diretório definido na propriedade 'dataDir'. Neste exemplo seria necessário criar o arquivo '/var/lib/zookeeperdata/myid' com o conteúdo '1' (sem aspas) para a máquina configurada na propriedade 'server.1', o mesmo arquivo com conteúdo '2' (sem aspas) para a máquina configurada na propriedade 'server.2', e assim por diante, para cada máquina existente no cluster. As portas 2888 e 3888 serão utilizadas para comunicação entre cada uma das máquinas do cluster e podem ser alteradas de acordo com a necessidade, desde que informadas na linha correspondete ao servidor em questão, no arquivo 'zoo.cfg' de todas as máquinas do cluster.
| Painel |
|---|
Certifique-se que o arquivo "myid" foi criado corretamente em cada máquina (na pasta definida pela propriedade dataDir), tendo o ID numérico do servidor como conteúdo. |
Com essa configuração em cada máquina do cluster, basta iniciá-las com o seguinte comando:
...
| Bloco de código |
|---|
| language | bash |
|---|
| theme | Eclipse |
|---|
| title | No Windows |
|---|
|
cd <ZOOKEEPER_HOME>/bin
zkServer.cmd start zoo.cfg |
Configurando o Apache® Solr
...
| Bloco de código |
|---|
| language | bash |
|---|
| theme | Eclipse |
|---|
| title | Inicializando o Solr no modo cloud |
|---|
|
ZK_HOST="<server1_address>:2181,<server2_address>:2181,<server3_address>:2181"
SOLR_HOST="<server>" |
Neste caso, os endereços <server1_address>, <server2_address> e <server3_address> no item ZK_HOST, são os mesmo informados anteriormente nos parâmetros 'server.X' do arquivo 'zoo.cfg', e a porta 2181 corresponde ao parâmetro clientPort informado nesse mesmo arquivo. As aspas devem ser mantidas.
O parâmetro <server> utilizado no item SOLR_HOST se refere ao endereço ou ip do próprio servidor que está configurando. As aspas devem ser mantidas.
A localização deste arquivo de configuração varia de acordo com o sistema operacional, e pode ser verificada na tabela abaixo:
| Sistema Operacional | Arquivo de Configuração | Localização |
|---|
| Linux | fluig_Indexer.in.sh | /etc/default/ |
| Windows | solr.in.cmd | [Instalação fluig Indexer]/solr/bin/ |
| Painel |
|---|
Após esta configuração, é necessário iniciar os serviços do Solr (fluig_Indexer) em todas as máquinas que o executarão para seguir com os próximos passos. |
| Nota |
|---|
|
É importante que o serviço de gerenciamento (ZooKeeper) seja iniciado antes do serviço de indexação (Solr), caso contrário, este último irá considerar que não há serviço de gerenciamento disponível. |
...
- O parâmetro '-d fluig' corresponde ao nome do diretório onde estão armazenadas as configurações utilizadas pela plataforma, instaladas por padrão juntamente com o serviço de indexação, no diretório 'fluig'. O comando irá efetuar o upload deste diretório para os endereços informados no parâmetro '-z'.
- O parâmetro '-n fluig' corresponde ao nome que esta configuração irá receber no serviço de gerenciamento (ZooKeeper) e será utilizado no próximo passo (criação da collection).
- O parâmetro '-z' informa a lista de serviços de gerenciamento (ZooKeeper) onde serão publicadas estas cofigurações, conforme detalhado anteriormente.
| Nota |
|---|
|
Como existe o ZooKeeper para gerenciar o cluster, este comando precisa ser executando apenas em uma das máquinas do Solr. |
Criação de collection
...
Cada empresa (tenant) criada no fluig é mapeada para uma collection no Apache® Solr. Quando em cluster, é necessário definir a quantidade de nós (shards) em que o índice será dividido e o fator de replicação (replicationFactor) das informações referentes à esta collection, através do seguinte comando:
...
- Informe o código numérico que será usado para a empresa criada no fluig em <ID do Tenant>.
- Neste caso o parâmetro '-d' corresponde ao nome da configuração armazenada no ZooKeeper (parâmetro '-n' do comando utilizado anteriormente para upload).
- Informe o número total de instâncias do Apache® Solr após o parâmetro '-replicationFactor'.
| Nota |
|---|
|
Como existe o ZooKeeper para gerenciar o cluster, este comando precisa ser executando apenas em uma das máquinas do Solr, mas as outras máquinas precisam estar com o Solr em execução. |
Configurando o fluig para usar o Indexer
...
Se o fluig tiver em execução, siga os passos abaixo:
| Deck of Cards |
|---|
| effectDuration | 0.5 |
|---|
| history | false |
|---|
| id | fi |
|---|
| effectType | fade |
|---|
|
| Card |
|---|
| default | true |
|---|
| id | 1 |
|---|
| label | Passo 1 |
|---|
|
- Acesse o fluig com o usuário 'wcmadmin':

|
| Card |
|---|
|
- Clique no menu Painel de Controle → Aba WCM → Configurações do Sistema:

|
| Card |
|---|
|
- Clique na Aba Parâmetros da Plataforma e localize as configurações do Servidor de Indexação:
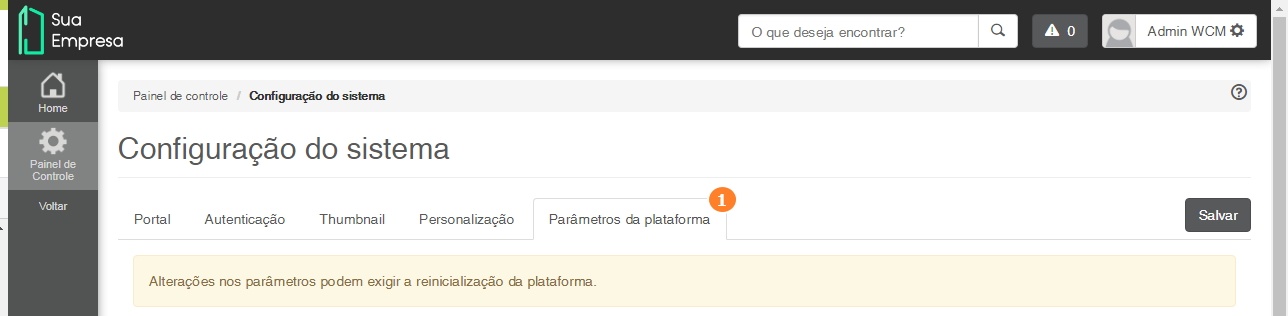
|
| Card |
|---|
|
- Configure da seguinte forma:
- URL de acesso ao Solr: Devem ser informados os endereços dos servidores onde estão sendo executados os serviços de gerenciamento (ZooKeeper), em uma lista de endereços separados por vírgula, da mesma forma que foram informados no parâmetro '-z' ao iniciar os serviços de indexação (Solr).
- Solr em Servidor Remoto: Deve estar ativado (ON).
- Solr em Cluster: Deve estar ativado (ON). Esta opção ativa o Solr em Cluster, necessária para ambientes em Cluster.

|
| Card |
|---|
|
- As alterações nos parâmetros exigem a reinicialização da plataforma. Portanto inicie os serviços na ordem correta.
|
|
- Se o fluig estiver parado, siga os passos abaixo:
| Deck of Cards |
|---|
| effectDuration | 0.5 |
|---|
| history | false |
|---|
| id | fi2 |
|---|
| effectType | fade |
|---|
|
| Card |
|---|
| default | true |
|---|
| id | 1 |
|---|
| label | Passo 1 |
|---|
|
- No servidor onde está instalado o fluig, acesse o diretório [Instalação fluig]/repository/wcmdir/config e edite o arquivo configuration.properties. Caso o arquivo configuration.properties não exista, crie um novo arquivo com este nome.
| Bloco de código |
|---|
| language | js |
|---|
| theme | Eclipse |
|---|
| title | configuration.properties |
|---|
| totvs/solrURL=10.171.70.21:2181,10.171.70.22:2181,10.171.70.23:2181
totvs/solrCloud=true
totvs/solrRemote=true |
- Modifique o parâmetro 'totvs/solrURL' informando a lista de endereços dos servidores onde estão sendo executados os serviços de gerenciamento, da mesma forma que foram informados no parâmetro '-z' ao iniciar os serviços de indexação (Solr). Deverá ser informado apenas o IP ou hostname do servidor e a porta, sem o protocolo e contexto.
| Nota |
|---|
O parâmetro 'totvs/solrCloud' irá condicionar o fluig para ativar a opção do Solr em Cluster, necessária para ambientes em Cluster. |
|
| Card |
|---|
|
- Iniciar os serviços de fluig na ordem correta.
|
|
| HTML |
|---|
<script>
$("b:contains('oculto')").parent().parent().hide();
</script> |